PCM压缩编码规则及源码分析
1. What is PCM?
PCM(Pulse-code-modulation)是模拟信号以固定的采样频率转换成数字信号后的表现形式。
Sample Rate :
采样频率单位为:Hz。采样频率越高,音频质量越好,占用空间也越大。
Sign :
音频数据是否是有符号的。通常情况下都是有符号的。若是将有符号的数据当做无符号的数据来处理将会使声音听来很刺
Sample Size :
表示每一个采样数据的大小。通常该值为16-bit。
Byte Ordering :
字节序指的是little-endian还是big-endian。表示音频数据的存储字节序。通常均为little-endian。
Number of Channels :
标识音频是单声道(mono,1 channel)还是立体声(stereo,2 channels)。
通过以上五个数据我们就可以描述一个PCM数据,播放一个PCM数据需要的就是以上五个数据。
2. What does a PCM stream look like?
单声道:
+------+------+------+------+------+------+------+------+------+| 500 | 300 | -100 | -20 | -300 | 900 | -200 | -50 | 250 | +------+------+------+------+------+------+------+------+------+ 123123
每个整数占据2个字节(16-bit),9个采样也就是18字节的数据。每个采样的整数大小最小为 -32768,最大为 32768 。根据采样数据的位置和值画一个图的话,就会得到像播放器上那样的波浪形图。
我们可以像下面伪代码示例这样将数据读入一个C语言数组 :
FILE *pcmfileint16_t *pcmdata; pcmfile = fopen(your pcm data file); pcmdata = malloc(size of the file);fread(pcmdata, sizeof(int16_t), size of file / sizeof(int16_t), pcmfile); 1234512345
如果我们将这些数据送入声卡,我们就可以听到声音。当然我们需要告诉声卡这些数据的采样率。若我们告知声卡的采样率大于数据本身的采样率,那么这些数据的播放速度会高于其原始的速度。就是快放的功能。
立体声:
+----------+----------+---------+----------+---------+----------+---------+----------+----------+ | LFrame1 | RFrame1 | LFrame2 | RFrame2 | LFrame3 | RFrame3 | LFrame4 | RFrame4 | LFrame5 | +----------+----------+---------+----------+---------+----------+---------+----------+----------+ 123123
每一个frame是一个16-bit的采样点。左右声道的数据交叉存放。
3. Basic Audio Effects – Volume Control
现在让我们来看一下一些真实的波形图。最简单的就是正弦波了。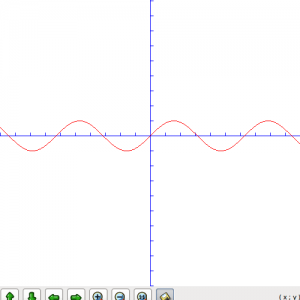
我们将波形的振幅扩大五倍,图形如下: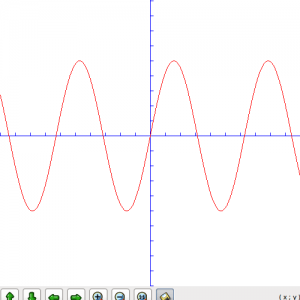
所以如果要增加PCM数据的音量,只需要将每一个采样的数据乘以一个系数就行了。如果我们的PCM数据有2048个字节,则包含了1024个采样。我们用如下的伪代码来扩大音量 :
int16_t pcm[1024] = read in some pcm data;for (ctr = 0; ctr < 1024; ctr++) {
pcm[ctr] *= 2;
}
12341234音量控制就是这么简单,但是要注意两点:
- 若采样点的数据乘以扩大系数之后的值 小于 -32768 或 大于 32768 ,则此处采样的数值只能取 -32768 或 32768
int16_t pcm[1024] = read in some pcm data;
int32_t pcmval; for (ctr = 0; ctr < 1024; ctr++) {
pcmval = pcm[ctr] * 2; if (pcmval < 32767 && pcmval > -32768) {
pcm[ctr] = pcmval
} else if (pcmval > 32767) {
pcm[ctr] = 32767;
} else if (pcmval < -32768) {
pcm[ctr] = -32768;
}
}
123456789101112123456789101112- 我们将采样点的数据乘以2并不代表将声音的音量扩大了两倍,事实上也的确如此。声音音量的增益系数与音量的关系如图:
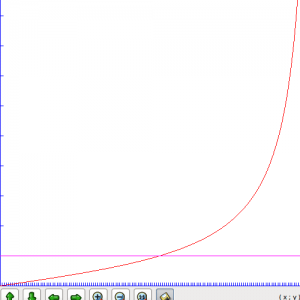
以上内容翻译自:http://www.ypass.net/blog/2010/01/pcm-audio-part-3-basic-audio-effects-volume-control/
4. How to change PCM Sample Rate
根据定义,Sample Rate表示每秒钟的采样个数,所以若是要改变音频的采样频率,我们只需要对采样点做适当的丢弃或者复制就可以。
比如:原始音频为opus编码,单声道,采样率为48kHz,采样点大小为16-bit。如何得到编码为speex,采样率为16kHz,采样大小为16-bit的音频?
我们需要以下几步:
- 将opus解码为PCM格式数据(叫做PCM1),此时的PCM1的采样率为48kHz
- 将PCM1的数据中第 3*n(n为从0开始的自然数) 个位置的采样点,丢弃3*n+1 和3*n+2位置的采样点。得到PCM2,此时的PCM2采样率为48kHz / 3 = 16kHz
- 将PCM2编码为speex数据
二. PCM压缩源代码
adpcm.h
#ifndef ADPCM_H
#define ADPCM_H
struct adpcm_state
{
int valprev;
int index;
};
extern void adpcm_coder(short *indata, signed char *outdata, int len, struct adpcm_state *state);
extern void adpcm_decoder(signed char *indata, short *outdata, int len, struct adpcm_state *state);
#endif /*ADPCM_H*/adpcm.c
/***********************************************************
Copyright 1992 by Stichting Mathematisch Centrum, Amsterdam, The
Netherlands.
All Rights Reserved
Permission to use, copy, modify, and distribute this software and its
documentation for any purpose and without fee is hereby granted,
provided that the above copyright notice appear in all copies and that
both that copyright notice and this permission notice appear in
supporting documentation, and that the names of Stichting Mathematisch
Centrum or CWI not be used in advertising or publicity pertaining to
distribution of the software without specific, written prior permission.
STICHTING MATHEMATISCH CENTRUM DISCLAIMS ALL WARRANTIES WITH REGARD TO
THIS SOFTWARE, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY AND
FITNESS, IN NO EVENT SHALL STICHTING MATHEMATISCH CENTRUM BE LIABLE
FOR ANY SPECIAL, INDIRECT OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES
WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN
ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT
OF OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
******************************************************************/
/*
** Intel/DVI ADPCM coder/decoder.
**
** The algorithm for this coder was taken from the IMA Compatability Project
** proceedings, Vol 2, Number 2; May 1992.
**
** Version 1.2, 18-Dec-92.
**
** Change log:
** - Fixed a stupid bug, where the delta was computed as
** stepsize*code/4 in stead of stepsize*(code+0.5)/4.
** - There was an off-by-one error causing it to pick
** an incorrect delta once in a blue moon.
** - The NODIVMUL define has been removed. Computations are now always done
** using shifts, adds and subtracts. It turned out that, because the standard
** is defined using shift/add/subtract, you needed bits of fixup code
** (because the div/mul simulation using shift/add/sub made some rounding
** errors that real div/mul don't make) and all together the resultant code
** ran slower than just using the shifts all the time.
** - Changed some of the variable names to be more meaningful.
*/
#include "adpcm.h"
#include <stdio.h> /*DBG*/
#ifndef __STDC__
#define signed
#endif
/* Intel ADPCM step variation table */
static int indexTable[16] = {
-1, -1, -1, -1, 2, 4, 6, 8,
-1, -1, -1, -1, 2, 4, 6, 8,
};
static int stepsizeTable[89] = {
7, 8, 9, 10, 11, 12, 13, 14, 16, 17,
19, 21, 23, 25, 28, 31, 34, 37, 41, 45,
50, 55, 60, 66, 73, 80, 88, 97, 107, 118,
130, 143, 157, 173, 190, 209, 230, 253, 279, 307,
337, 371, 408, 449, 494, 544, 598, 658, 724, 796,
876, 963, 1060, 1166, 1282, 1411, 1552, 1707, 1878, 2066,
2272, 2499, 2749, 3024, 3327, 3660, 4026, 4428, 4871, 5358,
5894, 6484, 7132, 7845, 8630, 9493, 10442, 11487, 12635, 13899,
15289, 16818, 18500, 20350, 22385, 24623, 27086, 29794, 32767
};
void adpcm_coder(short *indata, signed char *outdata, int len, struct adpcm_state *state)
{
short *inp;/* Input buffer pointer */
signed char *outp;/* output buffer pointer */
int val;/* Current input sample value */
int sign;/* Current adpcm sign bit */
int delta;/* Current adpcm output value */
int diff;/* Difference between val and valprev */
int step;/* Stepsize */
int valpred;/* Predicted output value */
int vpdiff;/* Current change to valpred */
int index;/* Current step change index */
int outputbuffer;/* place to keep previous 4-bit value */
int bufferstep;/* toggle between outputbuffer/output */
outp = (signed char *)outdata;
inp = indata;
valpred = state->valprev;
index = state->index;
step = stepsizeTable[index];
bufferstep = 1;
for ( ; len > 0 ; len-- ) {
val = *inp++;
/* Step 1 - compute difference with previous value */
diff = val - valpred;
sign = (diff < 0) ? 8 : 0;
if ( sign ) diff = (-diff);
/* Step 2 - Divide and clamp */
/* Note:
** This code *approximately* computes:
** delta = diff*4/step;
** vpdiff = (delta+0.5)*step/4;
** but in shift step bits are dropped. The net result of this is
** that even if you have fast mul/div hardware you cannot put it to
** good use since the fixup would be too expensive.
*/
delta = 0;
vpdiff = (step >> 3);
if ( diff >= step ) {
delta = 4;
diff -= step;
vpdiff += step;
}
step >>= 1;
if ( diff >= step ) {
delta |= 2;
diff -= step;
vpdiff += step;
}
step >>= 1;
if ( diff >= step ) {
delta |= 1;
vpdiff += step;
}
/* Step 3 - Update previous value */
if ( sign )
valpred -= vpdiff;
else
valpred += vpdiff;
/* Step 4 - Clamp previous value to 16 bits */
if ( valpred > 32767 )
valpred = 32767;
else if ( valpred < -32768 )
valpred = -32768;
/* Step 5 - Assemble value, update index and step values */
delta |= sign;
index += indexTable[delta];
if ( index < 0 ) index = 0;
if ( index > 88 ) index = 88;
step = stepsizeTable[index];
/* Step 6 - Output value
if ( bufferstep ) {
outputbuffer = (delta << 4) & 0xf0;
} else {
*outp++ = (delta & 0x0f) | outputbuffer;
}*/
if ( bufferstep ) {
outputbuffer = delta & 0x0f;
} else {
*outp++ = ((delta << 4) & 0xf0) | outputbuffer;
}
bufferstep = !bufferstep;
}
/* Output last step, if needed */
if ( !bufferstep )
*outp++ = outputbuffer;
state->valprev = valpred;
state->index = index;
}
void adpcm_decoder(signed char *indata, short *outdata, int len, struct adpcm_state *state)
{
signed char *inp;/* Input buffer pointer */
short *outp;/* output buffer pointer */
int sign;/* Current adpcm sign bit */
int delta;/* Current adpcm output value */
int step;/* Stepsize */
int valpred;/* Predicted value */
int vpdiff;/* Current change to valpred */
int index;/* Current step change index */
int inputbuffer;/* place to keep next 4-bit value */
int bufferstep;/* toggle between inputbuffer/input */
outp = outdata;
inp = (signed char *)indata;
valpred = state->valprev;
index = state->index;
step = stepsizeTable[index];
bufferstep = 0;
for ( ; len > 0 ; len-- ) {
/* Step 1 - get the delta value */
if ( !bufferstep ) {
inputbuffer = *inp++;
delta = inputbuffer & 0xf;
} else {
delta = (inputbuffer >> 4) & 0xf;
}
bufferstep = !bufferstep;
/* Step 2 - Find new index value (for later) */
index += indexTable[delta];
if ( index < 0 ) index = 0;
if ( index > 88 ) index = 88;
/* Step 3 - Separate sign and magnitude */
sign = delta & 8;
delta = delta & 7;
/* Step 4 - Compute difference and new predicted value */
/*
** Computes 'vpdiff = (delta+0.5)*step/4', but see comment
** in adpcm_coder.
*/
vpdiff = step >> 3;
if ( delta & 4 ) vpdiff += step;
if ( delta & 2 ) vpdiff += step>>1;
if ( delta & 1 ) vpdiff += step>>2;
if ( sign )
valpred -= vpdiff;
else
valpred += vpdiff;
/* Step 5 - clamp output value */
if ( valpred > 32767 )
valpred = 32767;
else if ( valpred < -32768 )
valpred = -32768;
/* Step 6 - Update step value */
step = stepsizeTable[index];
/* Step 7 - Output value */
*outp++ = valpred;
}
state->valprev = valpred;
state->index = index;
}三、 adpcm编解码原理
1.adpcm编码原理
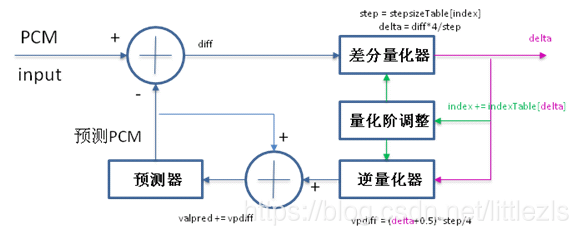
编码步骤:
- 求出输入的pcm数据与预测的pcm数据(第一次为上一个pcm数据)的差值diff;
- 通过差分量化器算出delta(通过index(首次编码index为0)求出step,通过diff和step求出delta)。delta即为编码后的数据;
- 通过逆量化器求出vpdiff(通过求出的delta和step算出vpdiff);
- 求出新的预测valpred,即上次预测的valpred+vpdiff;
- 通过预测器(归一化),求出当前输入pcm input的预测pcm值,为下一次计算用;
- 量化阶调整(通过delta查表及index,计算出新的index值)。为下次计算用;
2.adpcm解码原理
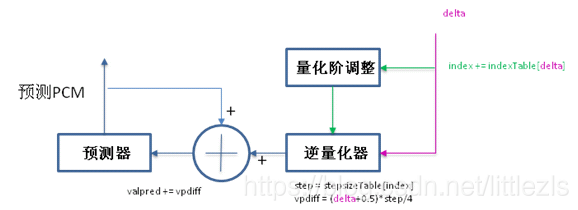
解码步骤(其实解码原理就是编码的第三到六步):
- 通过逆量化器求出vpdiff(通过存储的delta和index,求出step,算出vpdiff);
- 求出新的预测valpred,即上次预测的valpred+vpdiff;
- 通过预测器(归一化),求出当前输入pcm input的预测pcm值,为下一次计算用。预测的pcm值即为解码后的数据;
- 量化阶调整(通过delta查表及index,计算出新的index值)。为下次计算用;
注释说明
- 通过编码和解码的原理我们可以看出其实第一次编码的时候已经进行了解码,即预测的pcm。
- 因为编码再解码后输出的数据已经被量化了。根据计算公式delta = diff*4/step;vpdiff = (delta+0.5)*step/4;考虑到都是整数运算,可以推导出:pcm数据经过编码再解码生成的预测pcm数据,如果预测pcm数据再次编码所得的数据与第一次编码所得的数据是相同的。故pcm数据经过一次编码有损后,不论后面经过几次解码再编码都是数据一样,音质不会再次损失。即相对于第一次编码后,以后数据不论多少次编解码,属于无损输出。
3. ADPCM数据存放形式
本部分为adpcm数据存放说明,属于细节部分,很多代码解码出来有噪音就是因为本部分细节不对,所以需要仔细阅读。
1. adpcm 数据块介绍
adpcm数据是一个block一个block存放的,block由block header (block头) 和data 两者组成的。其中block header是一个结构,它在单声道下的定义如下:
Typedef struct{short sample0; //block中第一个采样值(未压缩)BYTE index; //上一个block最后一个index,第一个block的index=0;BYTE reserved; //尚未使用}MonoBlockHeader;123456对于双声道,它的blockheader应该包含两个MonoBlockHeader其定义如下:
typedaf struct{MonoBlockHeader leftbher;MonoBlockHeader rightbher;}StereoBlockHeader;12345在解压缩时,左右声道是分开处理的,所以必须有两个MonoBlockHeader;
有了blockheader的信息后,就可以不需要知道这个block前面数据而轻松地解出本block中的压缩数据。故adpcm解码只与本block有关,与其他block无关,可以只单个解任何一个block数据。
block的大小是固定的,可以自定义,每个block含的采样数nsamples计算如下:
//#define BLKSIZE 1024block = BLKSIZE * channels;//block = BLKSIZE;//ffmpegnsamples = (block - 4 * channels) * 8 / (4 * channels) + 1;12345
例如audition软件就是采用上面的,单通路block为1024bytes,2041个samples,双通路block为2048,也是含有2041个sample。
而ffmpeg采用block =1024bytes,即不论单双通路都为1024bytes,通过公式可以算出单双通路的samples数分别为2041和1017;
2. 单通路pcm格式:
| byte 0 byte 1 | byte 2 byte 3 | byte 4 byte 5 | byte 6 byte 7 | byte 8 byte 9 | … |
|---|---|---|---|---|---|
| sample0 | sample1 | sample2 | sample3 | sample4 | … |
单通路压缩为adpcm数据为 4bytes block head + raw data:
| byte 0 byte 1 | byte 2 | byte 3 | byte 4 | byte 5 | byte 7 | byte 8 | byte 9 | … |
|---|---|---|---|---|---|---|---|---|
| sample0 | index | reserved | data0 | data1 | data2 | data3 | data4 | … |
其中sample1编码后存data0低4位,sample2编码后存data0高四位...1
3. 双通路pcm格式:
| byte 0 byte 1 | byte 2 byte 3 | byte 4 byte 5 | byte 6 byte 7 | byte 8 byte 9 | … |
|---|---|---|---|---|---|
| sampleL0 | sampleR0 | sampleL1 | sampleR1 | sampleL2 | … |
双通路压缩为adpcm数据为 4bytes block L head + 4bytes block R head + 4bytes raw L data + 4bytes raw R data…:
adpcm双通路block head:
| byte 0 byte 1 | byte 2 | byte 3 | byte 4 byte 5 | byte 6 | byte 7 |
|---|---|---|---|---|---|
| sample0L | indexL | reservedL | sample0R | indexR | reservedR |
接着双通路raw压缩数据4byte L, 4byte R …:
| byte8 | byte9 | byte10 | byte11 | byte12 | byte13 | byte14 | byte15 | byte16 | byte17 | byte17 | … |
|---|---|---|---|---|---|---|---|---|---|---|---|
| data0L | data1L | data2L | data3L | data0R | data1R | data2R | data3R | data4L | data5L | data6L | … |
4. 编解码代码实现
需要特别留意双声道的处理和当数据不够1 block时的处理方式:
如果最后不够1block,多于1个,还按照1block进行编码,保存长度为1block。
如果最后只多余1个采样点,那就只保存blockheader,后面不用再保存了。
但在wav头告诉其实际采样点数,为将来解码还原相同的的采样点数。
代码包含了编码和解码测试用例,实现先编码再解码。欢迎交流学习
完整代码下载地址(本文只是详细说明了adpcm编解码,如果想wav文件编解码正确需要下载完整代码。
完整代码为0x0011 /* Intel’s DVI ADPCM */的编码解码代码实现。包括单双通路的处理和最后数据不是整块block的处理):
https://download.csdn.net/download/littlezls/10750913