使用教程:
安装python3(centos):https://eqblog.com/centos-install-python3-6-4.html
安装requests库:pip3 install requests
mkdir pic#创建个储存图片的文件夹
cd pic
python3 1024_spider_th.py
执行以上命令即可
update:只抓了270页以前,以后的有许多图片都已经失效了
应loc基友要求,特别写了这个
一开始是单线程的,但是有大佬说多线程很快(主要是加个多线程简单)
所以,就改成了多线程下载
已经测试可用,建议在网速好的环境用,下载速度很快。
线程是以有多少张图片算的,多少张图片就多少线程
我用维也纳CN2测试的,差不多5分钟可用爬一页
另外不支持续传,如果已存在文件夹会自动跳过
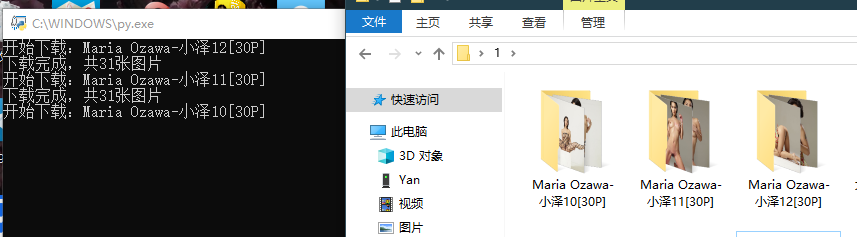
使用效果图:
import requests
import threading
import re
import os
class myThread (threading.Thread): #继承父类threading.Thread
def __init__(self, url, dir, filename):
threading.Thread.__init__(self)
self.threadID = filename
self.url = url
self.dir = dir
self.filename=filename
def run(self): #把要执行的代码写到run函数里面 线程在创建后会直接运行run函数
download_pic(self.url,self.dir,self.filename)
def download_pic(url,dir,filename):
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36Name','Referer':'https://t66y.com'}
req=requests.get(url=url,headers=headers)
if req.status_code==200:
with open(str(dir)+'/'+str(filename)+'.jpg','wb') as f:
f.write(req.content)
try:
flag=1
while flag<=270:
base_url='https://t66y.com/'
page_url='https://t66y.com/thread0806.php?fid=8&search=&page='+str(flag)
get=requests.get(page_url)
article_url=re.findall(r'<h3><a href="(.*)" target="_blank" id="">(?!<.*>).*</a></h3>',str(get.content,'gbk',errors='ignore'))
for url in article_url:
threads=[]
tittle=['default']
getpage=requests.get(str(base_url)+str(url))
tittle=re.findall(r'<h4>(.*)</h4>',str(getpage.content,'gbk',errors='ignore'))
file=tittle[0]
if os.path.exists(file)==False:
os.makedirs(file)
img_url=re.findall(r'<input src=\'(.*?)\'',str(getpage.content,'gbk',errors='ignore'))
filename=1
print('开始下载:'+file)
for download_url in img_url:
thread=myThread(download_url,file,filename)
thread.start()
threads.append(thread)
filename=filename+1
for t in threads:
t.join()
print('下载完成,共'+str(filename)+'张图片')
else:
print('文件夹已存在,跳过')
print('第'+str(flag)+'页下载完成')
flag=flag+1
except:
print('程序错误,退出')
多线程代码:
https://eqblog.com/script/1024_spider_th.py
单线程代码:
https://eqblog.com/script/1024_spider.py